Knowit Experience
På Nordens största digitalbyrå har vi närmare 1 000 specialister som i gränslinjen mellan teknik och kommunikation skapar digitala upplevelser som stärker varumärke och kundrelationer. I dag finns Experience i Sverige, Norge, Danmark, Finland och Polen.

Genom att koppla samman data och insikt med kreativitet och teknik skapar vi kundupplevelser och robusta lösningar med användaren i centrum. Design, utveckling av digitala produkter och plattformar, varumärke, marknadsföring, e-handel och dataanalys är våra främsta expertområden.
I våra uppdrag är vi oftast på plats hos våra kunder för att stötta och vara nära, ibland driver vi projekt in-house. Med sju kontor i Sverige har vi en stark lokal närvaro och samarbetar gärna över ländernas gränser för att skapa de bästa lösningarna och upplevelserna.
Tvärfunktionella och agila
I agila och tvärfunktionella team skapar vi starka digitala kundupplevelser genom webapplikationer, app-lösningar, kommunikationskoncept och innovativa tjänster som bidrar till att förenkla människors vardag och förstärka kopplingar mellan varumärken och användare.
Knowit Experience erbjuder kompetenser inom:
- Digitala tjänster och plattformar för webb och mobil
- Innovation och affärstillväxt
- Interaktiv design, tjänstedesign, businessdesign
- Digital handel
- Varumärkesstrategi och visuell identitet
- Datadriven och automatiserad marknadsföring
Datadrivna kundupplevelser för alla
Våra kunder finns i alla delar av samhället och inom flera olika branscher – bland annat inom skola, vård och myndigheter samt e-handel, transport, bank och finans. Genom riktad digital närvaro och unika användarupplevelser via webb och sociala medier, hjälper vi kunder att nå deras affärskritiska mål och stärka kundlojaliteten. Tusentals människor använder varje dag de digitala lösningar som vi tillsammans med våra kunder tar fram.
Som Nordens största digitalbyrå har Knowit Experience kompetens som sträcker sig från varumärke och design till datadrivna e-handelsplattformar. Det innebär att vi hjälper våra kunder att förflytta sina varumärken och skapa unika kundupplevelser.
Kenneth Gvein
Affärsområdeschef, Knowit Experience.
Utvalda samarbeten vi är stolta över:


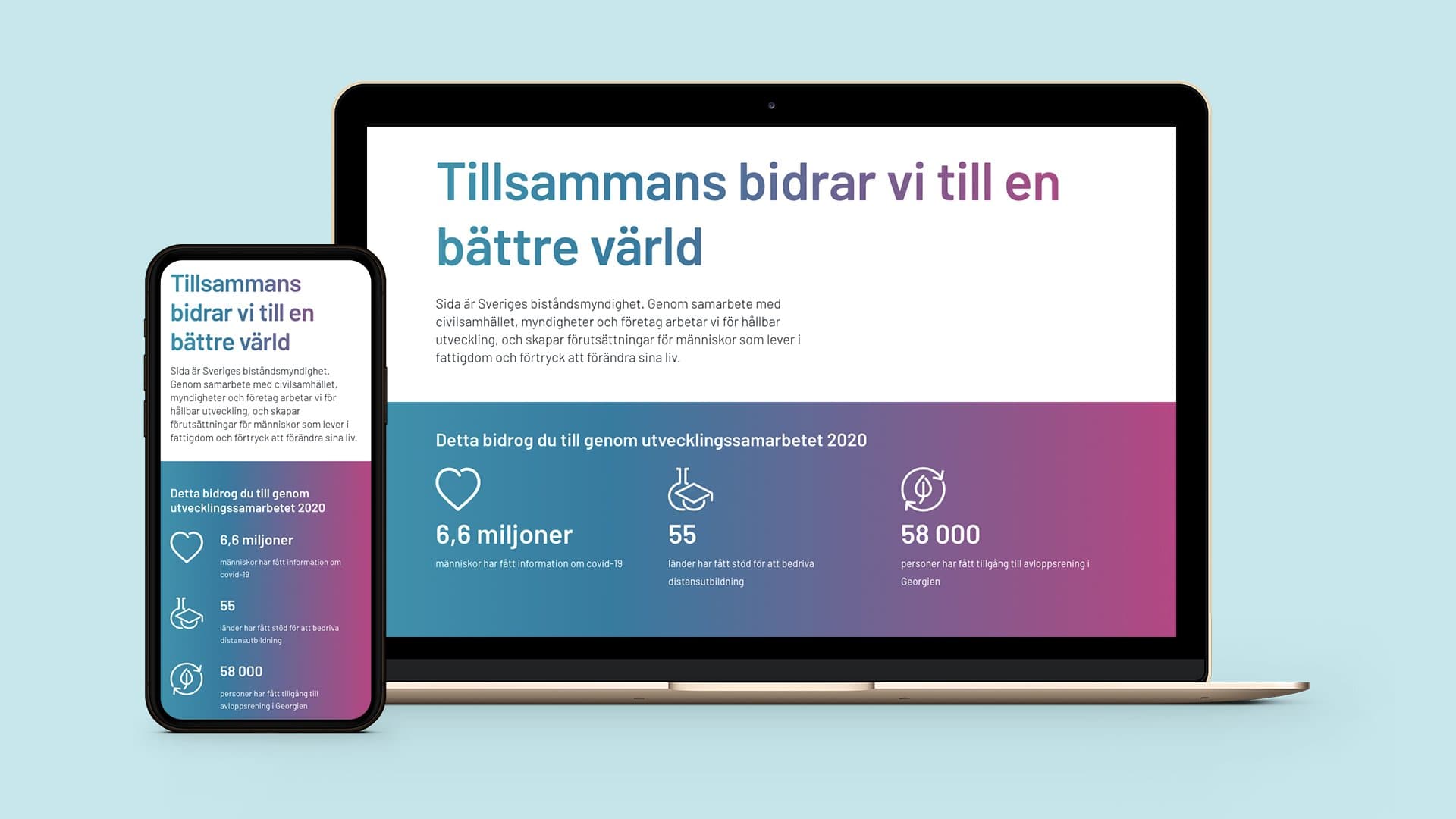
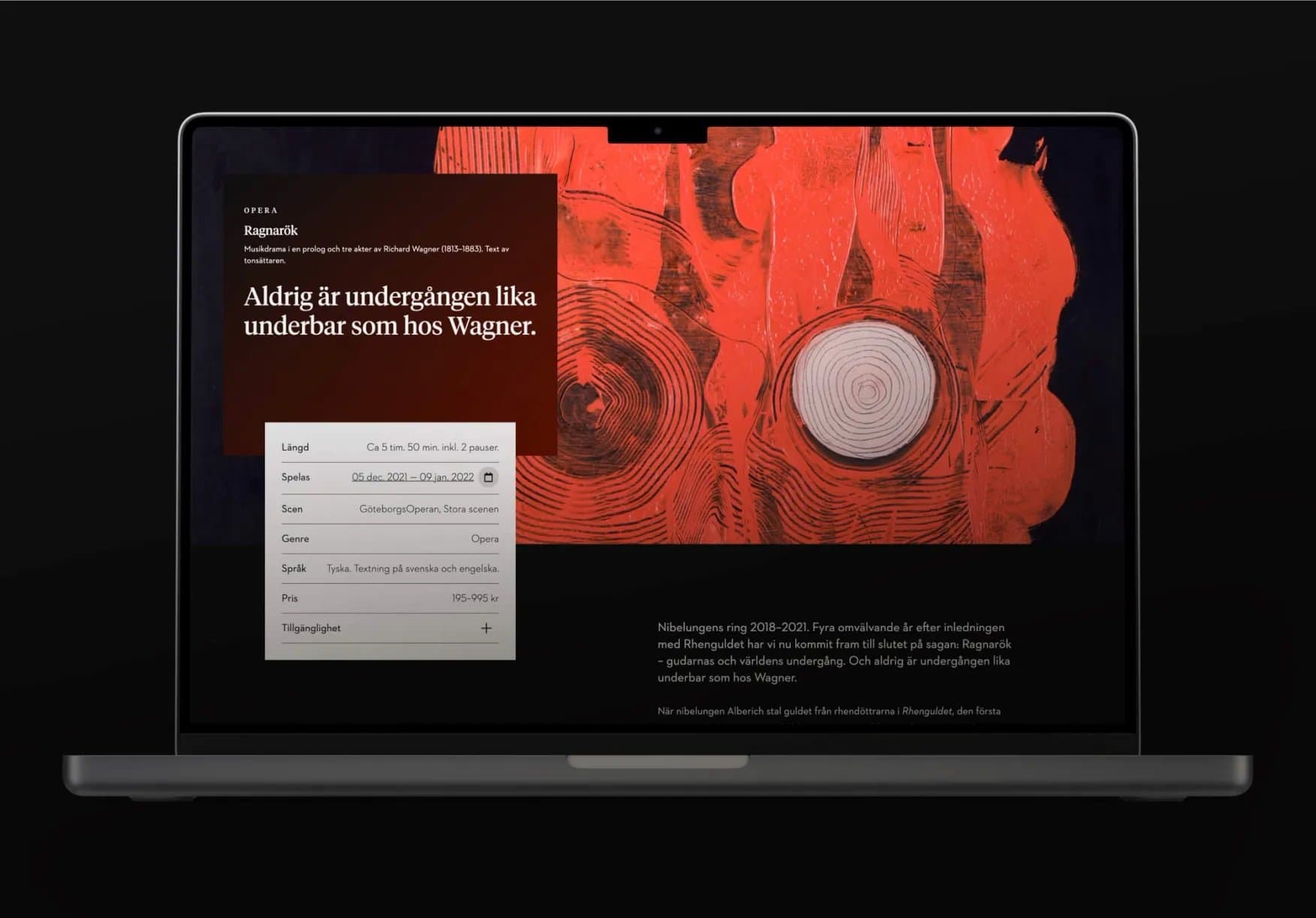

Tankar och idéer om allt som rör det digitala
Genom vår blogg delar vi våra trendspaningar, guider och insikter. Kunskapsdelning är bra och viktigt tycker vi. Enjoy!
Djupdyk i digital kunskap
I vår podd Digitalterapi pratar vi med gäster från olika branscher och bakgrund där vi utforskar deras digitala hang-up och fördjupar vår kunskap och förståelse för ämnen inom e-handel, kundupplevelser, appar, e-hälsa, tillgänglighet, hållbarhet, design och teknik.
Bli en del av vårt team!
Tycker du att vi verkar vara ett schysst gäng? Vi är alltid på jakt efter talanger som vill jobba med att ta fram innovativa, digitala lösningar som bidrar till en bättre värld. Har du letat, men ännu inte hittat den rätta arbetsplatsen kanske vi är en match!
900+
medarbetare
Skapar unika användarupplevelser som stärker varumärke och kundrelationer.
5
länder
Vi finns i Sverige, Norge, Danmark, Finland och Polen.